Table of Contents
- Getting Started with Data Engineering: Key Installations of Java, Spark, \& Python PySpark
Getting Started with Data Engineering: Key Installations of Java, Spark, & Python PySpark
In this guide, I will show how to set up a complete data engineering setup including Java, Full Hadoop, Python, and PySpark. Additionally, I'll describe the significance of setting different environment variables, their roles, and the key differences between Pyspark and a complete Spark setup.
Install Java [Oracle JDK]
I’ve opted for the traditional Java, bringing with it the familiar folder system. Feel free to explore variants like OpenJDK.
- Download the JDK 11 (or later) installer from Oracle JDK Downloads page
-
Install JDK in the default directory (typically
C:\Program Files\Java\jdk-11). -
To verify the installation, enter
java -versionin your command prompt. You should see output similar to this: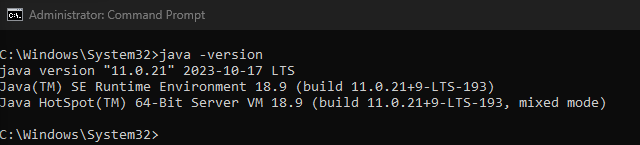
Install Full Apache SPARK
-
Download
spark-3.5.0-bin-hadoop3.tgzfrom spark.apache.org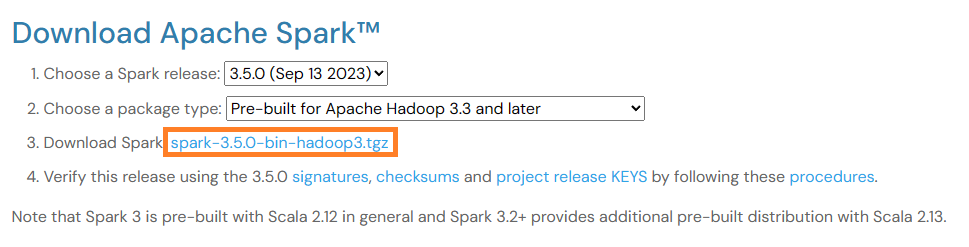
-
Create a folder
C:\Spark. Place the unzipped contents ofspark-3.5.0-bin-hadoop3.tgzinside it. YourC:\Sparkfolder should now contain lib, bin etc.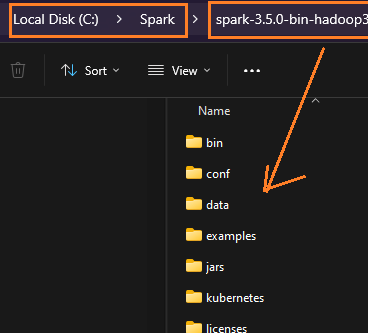
- Establish this folder structure:
C:\hadoop\bin. -
Download
winutils.exefrom github/cdarlint and place it insideC:\hadoop\bin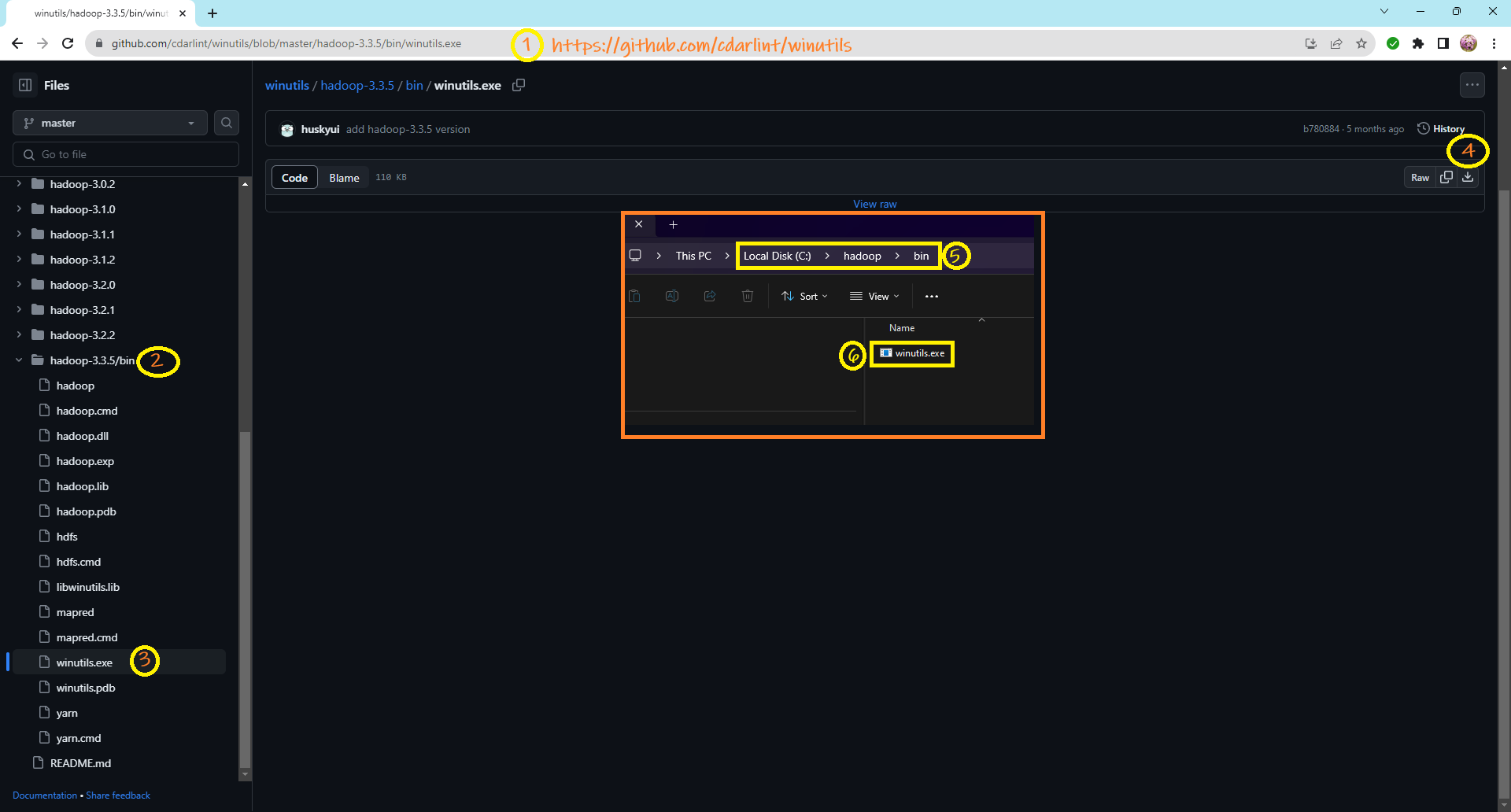
Install Python [python.org]
- Download
python-3.12.0-amd64.exe(or similar) from the Python Downloads page-
Execute the downloaded installer and opt for Customize Installation. Ensure you select Add python.exe to PATH.
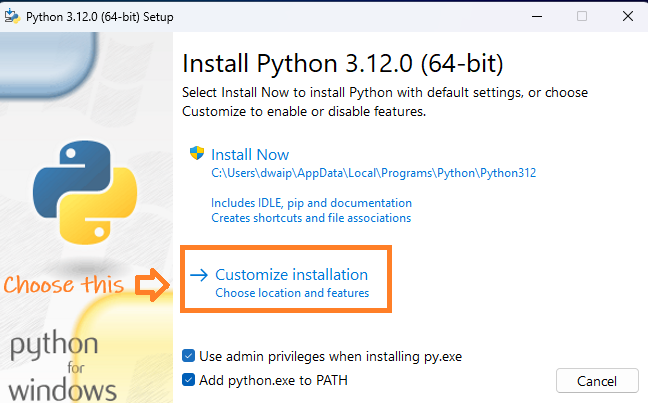
-
Proceed with all optional features and click Next.
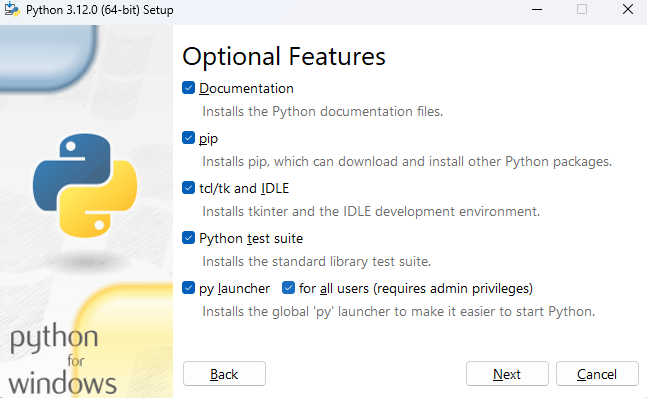
-
In Advanced Options, select “Install Python 3.12 for all users”.
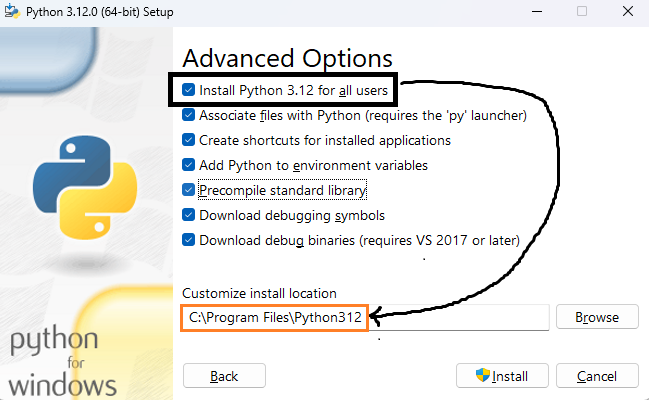
-
A successful setup should show up in a Setup Success message.
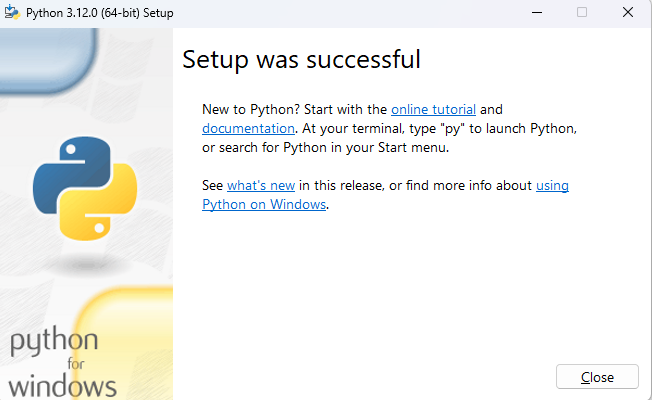
-
Verify the installation by typing
python --versionin your command prompt. The Python version number indicates a successful installation.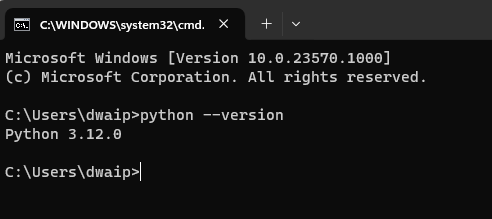
-
Set Env Variables
Entries
Navigate to Run ➤ SYSDM.CPL ➤ Advanced ➤ Environment Variables, and create or set these environment variables at the system (recommended) or user levels:
| Variable | Value |
|---|---|
JAVA_HOME | C:\Program Files\Java\jdk-11 |
SPARK_HOME | C:\Spark |
HADOOP_HOME | C:\hadoop |
PYSPARK_PYTHON | C:\Python39\python.exe |
| Path | %JAVA_HOME%\bin |
%SPARK_HOME%\bin | |
%HADOOP_HOME%\bin |
For a PowerShell command to set these variables with Admin privileges, remember to change 'Machine' (for system-wide level) to 'User' (for user level) as required.
Explanation
Link python.exe with PYSPARK_PYTHON
We set the PYSPARK_PYTHON environment variable to C:\Python39\python.exe to specify which Python executable Spark should use. This is vital, particularly if you have multiple Python installations.
%JAVA_HOME%\bin to PATH
While C:\Program Files\Common Files\Oracle\Java\javapath might already be in your system’s Path environment variable, it’s generally advisable to add %JAVA_HOME%\bin to your Path. This ensures your system uses the JDK’s executables, rather than those from another Java installation.
Install Pyspark
Background
If your code involves creating a Spark session and dataframes, you’ll need PySpark Libraries. Install it using pip install pyspark. This does two things:
- Installs the libraries
- Installs a ‘miniature, standalone’ Spark environment for testing
However, in our case, we don’t need the ‘miniature Spark’ that comes with PySpark libraries. We’ll manage potential Spark conflicts with the SPARK_HOME variable set to our full Spark environment.
Install Pyspark System-Wide
Open a command prompt with Admin privilege. Use pip (included with our Python) and execute pip install pyspark for a system-wide installation.
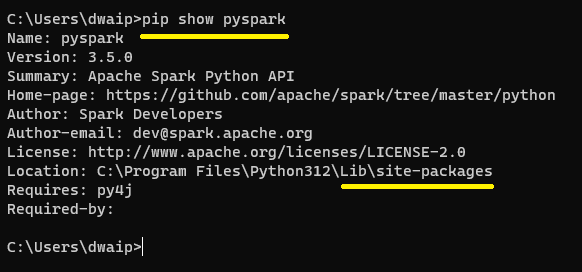
Check the Installation
After installation, confirm if PySpark is in the global site-packages:
pip show pyspark
The Location: field in the output reveals the installation location.
See Actual Working
Test your PySpark installation by starting a Spark session in a Python environment:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("TestApp") \
.getOrCreate()
print(spark.version)
spark.stop()
If Spark starts without errors, your PySpark setup with Python is successful.
Appendix
PYSPARK_PYTHON Overview
-
Selects Python Interpreter: Designates which Python version Spark executors should use for UDFs and transformations. Key in setups with multiple Python versions.
-
Uniformity in Clusters: Guarantees that all cluster nodes use the same Python environment, maintaining consistency in PySpark.
Pyspark Vs Full Spark Overview
I have put this in another section here. Read More..
© D Das
📧 das.d@hotmail.com | ddasdocs@gmail.com