Table of contents
- Overview
- What is Spark?
- Spark Architecture
- Spark Lifecycle
- What is Apache Hive?
- What is Hadoop?
- Is Spark replacing MapReduce?
- Is branded Spark (Synapse/Databricks) replacing traditional Spark, Hadoop, and Hive?
- Never heard of Hive. We use only Spark and Synapse Analytics.
- Spark RDDs
- Spark In-memory computing
Overview
What is Spark?
Its mainly a processing engine more like Mapreduce v2. It has no internal storage sytem like HDFS, but uses external file system lie ADLS, HDFS, S3 etc. Its processing engine is called Spark Core. It has standalone resource manager by default to manage its clusters.
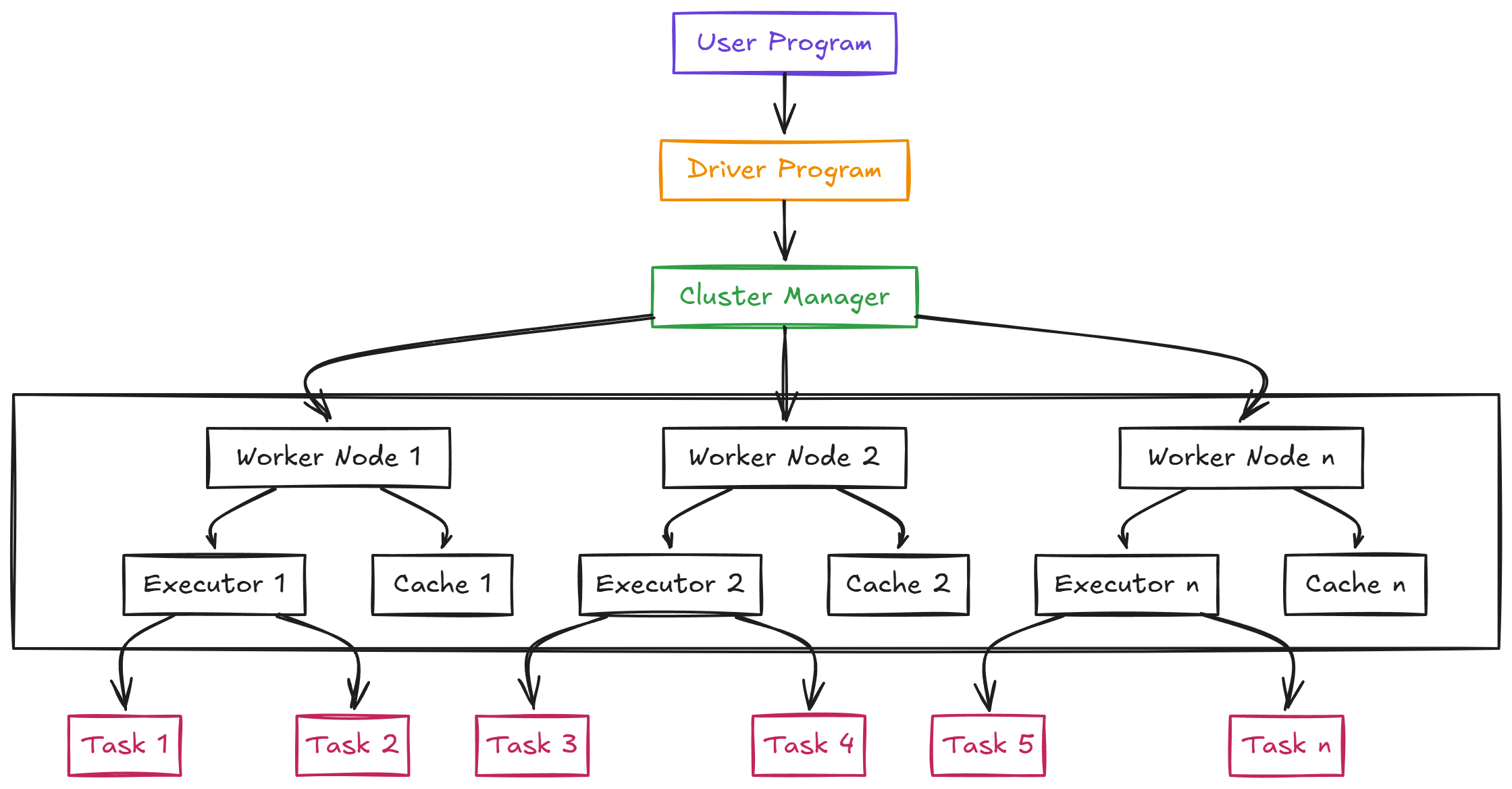
Spark Architecture
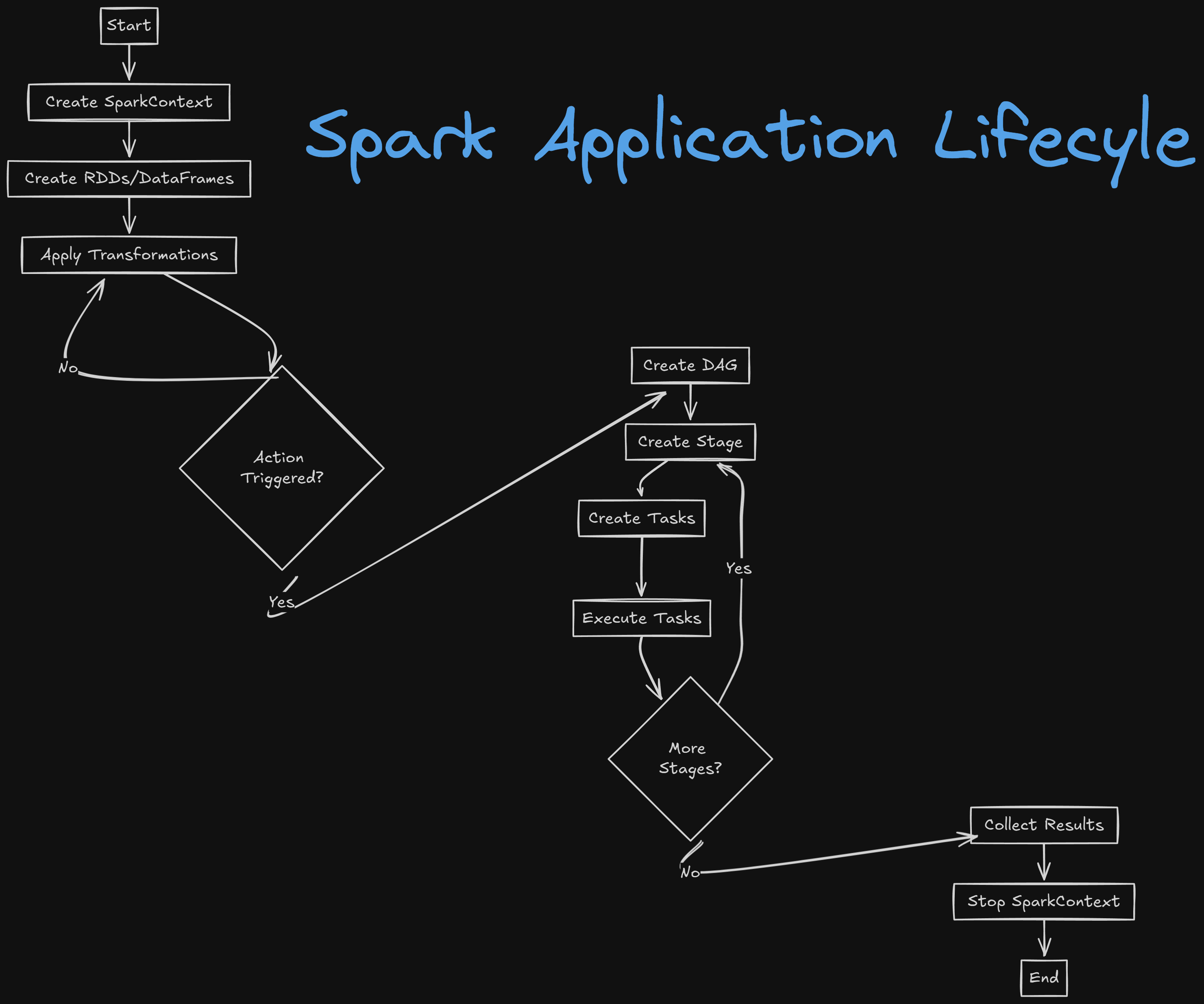
Spark Lifecycle
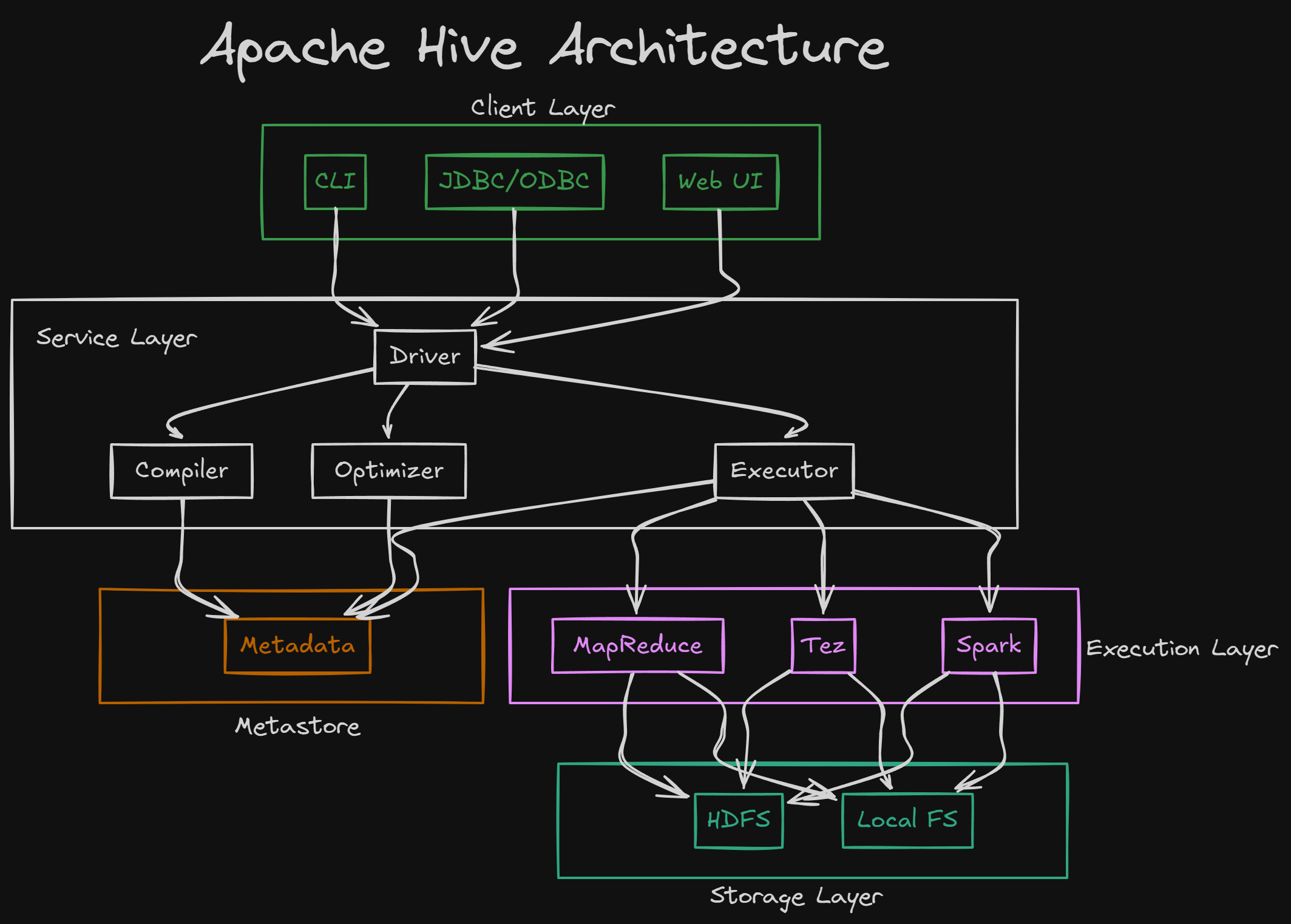
What is Apache Hive?
Apache Hive is a database like MSSQL Server. Its actually a data warehouse. It stores data in Hadoop File system(HDFS) as tables. Hive’s query language is called HiveQL, similar to SQL. he Hive metastore stores information about Hive tables. Developed by Facebook, Hive later became an Apache project.
What is Hadoop?
Hadoop is a distributed file system and processing framework similar to an MSSQL cluster but designed for handling large-scale file systems and big data. Here are its main components:
- Hadoop Distributed File System (HDFS): The file system for big data, akin to NTFS or FAT in traditional systems.
- MapReduce: The older generation of big data processing, similar to Spark.
- YARN (Yet Another Resource Negotiator): The cluster manager.
- Hadoop Common: The set of shared libraries and utilities.
Is Spark replacing MapReduce?
Yes, Spark is like the next version of MapReduce.
Is branded Spark (Synapse/Databricks) replacing traditional Spark, Hadoop, and Hive?
Imagine your company is new to data engineering and needs to process a lot of data. How long will it take to set up with Azure compared to using free open-source products on bare metal?
With Azure, you just sign up and create the setup with a few clicks. If the company has the budget, the entire setup takes about an hour. On the other hand, using traditional Spark, Hive, and Hadoop, setting up servers, networks, installation, configuration, and connectivity can become a year-long project.
That’s the difference between open-source and paid services. Open-source is free but risky. Paid services cost money but are easy, fast, accountable, and well-maintained.
Never heard of Hive. We use only Spark and Synapse Analytics.
If you always use branded products like Synapse and Databricks, you might not use Hive much. However, Hive catalogs are still used in Databricks. Just run a command like DESCRIBE EXTENDED TableName, and you’ll see where Hive is involved. But you don’t have to worry about the setup.
Spark RDDs
Spark In-memory computing
When we talk about in-memory its not just conventioal caching. Its actually storing data in RAM, processing in RAM etc. So, spark uses it and thats why its faster than mapreduce.