Pandas vs Spark
Here is a question from Microsoft Fabric Certificaiton exam:
You have a Parquet file named Customers.parquet uploaded to the Files section of a Fabric lakehouse.
You plan to use Data Wrangler to view basic summary statistics for the data before you load it to a Delta table.
You open a notebook in the lakehouse.
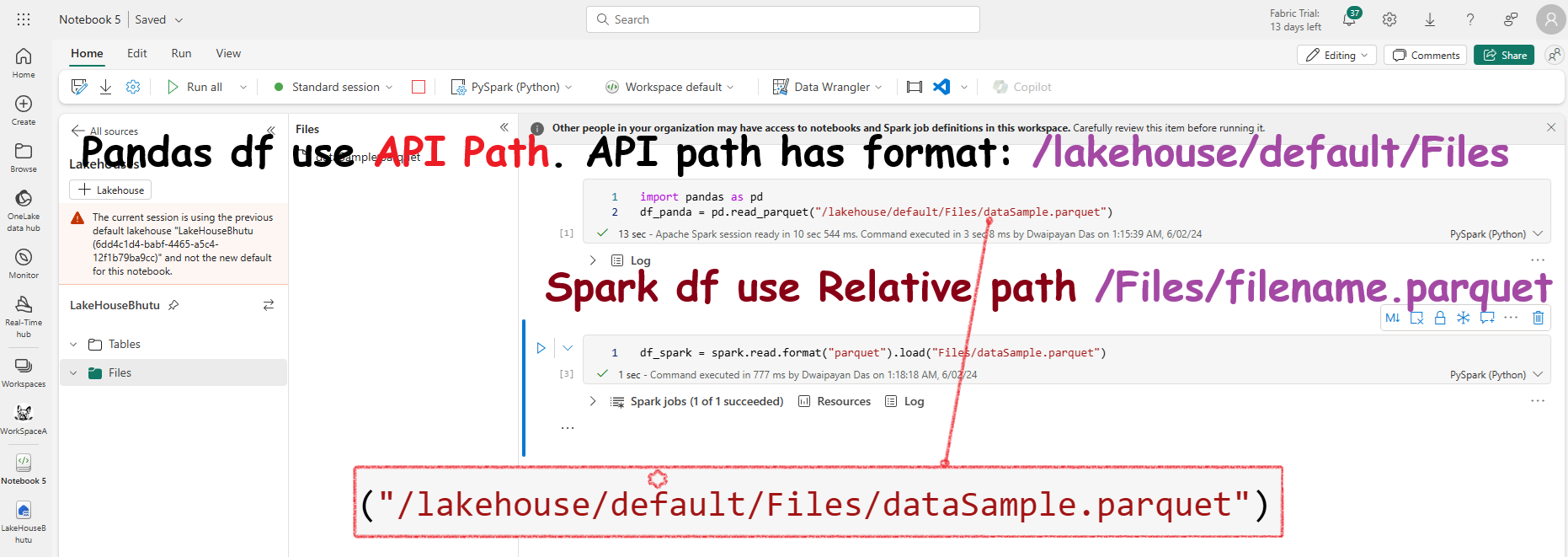
You need to load the data to a pandas DataFrame.
Which PySpark code should you run to complete the task?
Select only one answer.
df = pandas.read_parquet("/lakehouse/default/Files/Customers.parquet")
df = pandas.read_parquet("/lakehouse/Files/Customers.parquet") This answer is incorrect.
import pandas as pd df = pd.read_parquet("/lakehouse/default/Files/Customers.parquet") This answer is correct.
import pandas as pd df = pd.read_parquet("/lakehouse/Files/Customers.parquet") To load data to a pandas DataFrame, you must first import the pandas library by running import pandas as pd. Pandas DataFrames use the File API Path vs. the File relative path that Spark uses. The File API Path has the format of lakehouse/default/Files/Customers.parquet.